1. Inverted Index in memory
Small amount of data that you can load all terms and docid in memory
21bytes terms on avg and 1000 docids with 4 bytes int. And if you have 50 % of 4GB ram commodity machines, you can handle 80,000,000 terms.
Covid19:[2, 17, 678, 898, 9886]
sockcrush:[56, 89, 222, 678, 5678, 98760]
.
.
.
2. Inverted Index on DiskTerm:docid in a file
| I | 1 | Bearish | 2 | |
| Covid19 | 1 | Covid19 | 1 | |
| I | 1 | Crash | 2 | |
| You | 1 | SORT ==> | I | 1 |
| Told | 1 | I | 1 | |
| Stock | 2 | Stock | 2 | |
| Bearish | 2 | Told | 1 | |
| Crash | 2 | You | 1 |
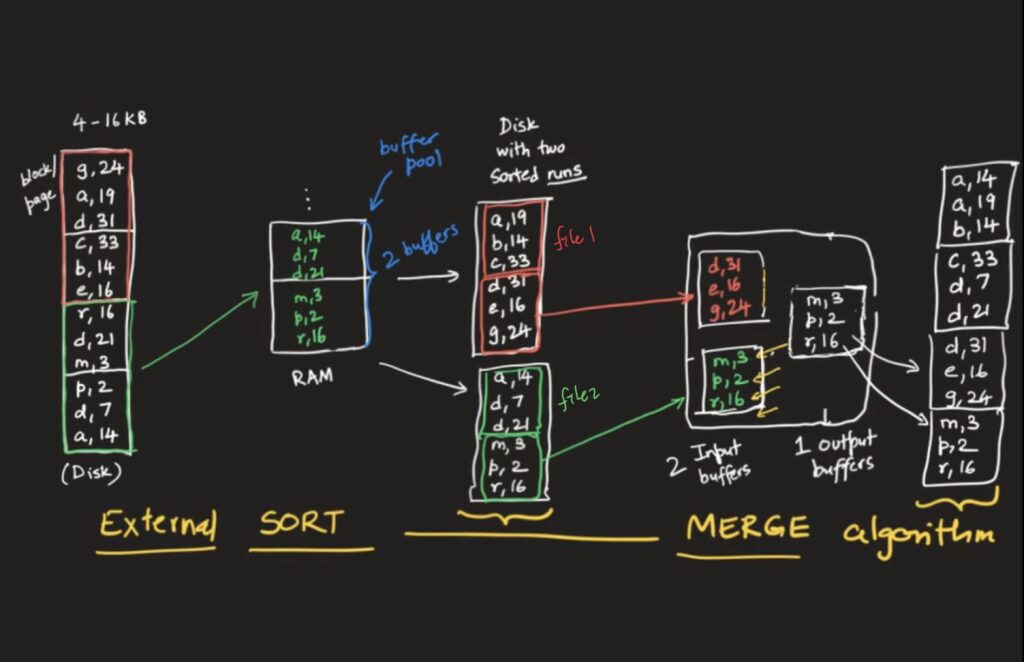
You can do it by External sort and Merge using Files.
Merge can be multiple phases due to # of files. It merges to one global sorted file.
k-way external sort-merge O(logk)*O(nk) with min-heap with k values.
Related leetcode problem
5. Inverted Index on Muti Disks-Map Reduce (altogether with GFS, External sort and merge to ss Table)
50 billion docs
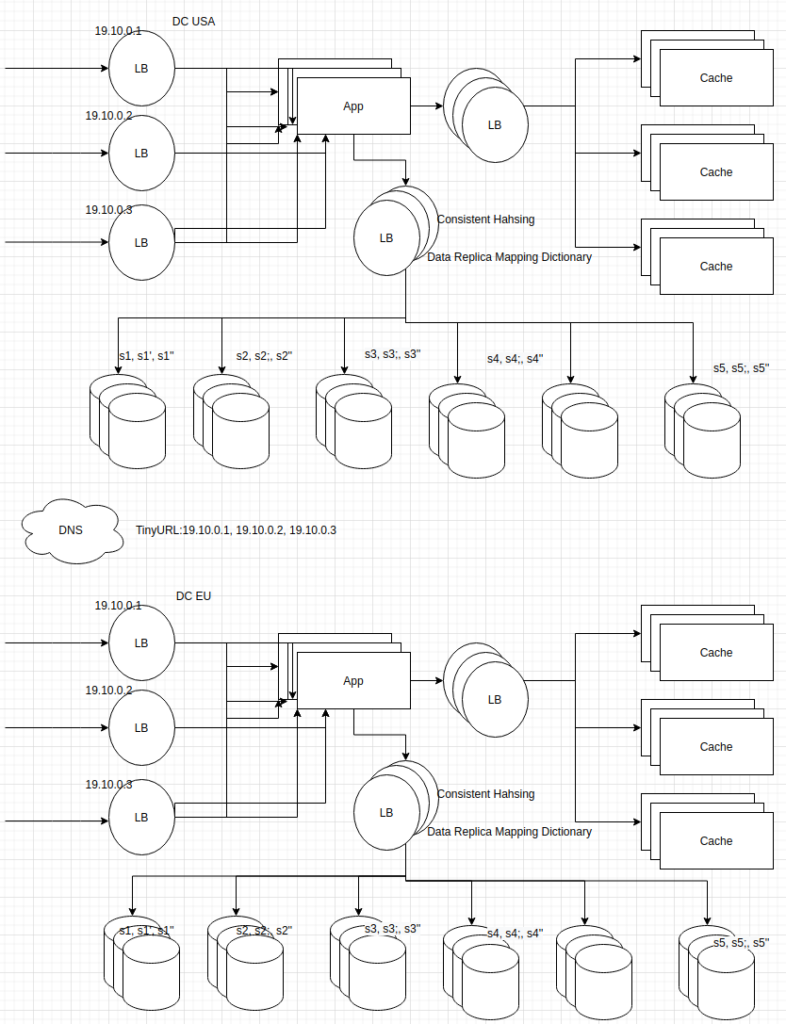
a. Distributed File System (GFS) because the SS Table(inverted index) is huge.
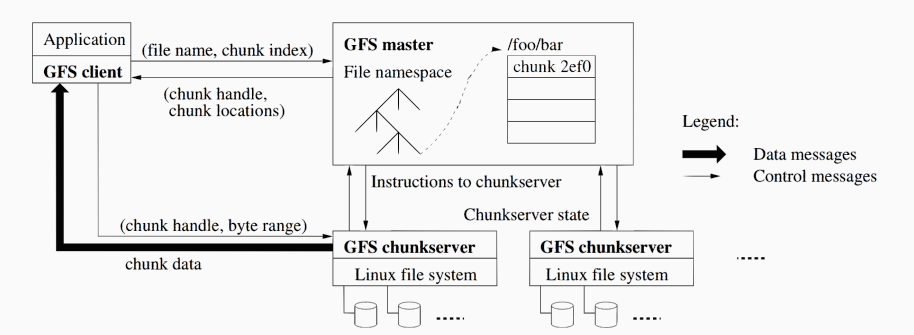
Master knows its chunks and can answer whic machine the filename “ss table” file resides and location of the files in the machine.
SS Table file : c1 -> s1, s1′, s1”
c2 -> s2,s2′, s2”
c3 -> s3, s3′, s3”
cn -> sn, sn’, sn”
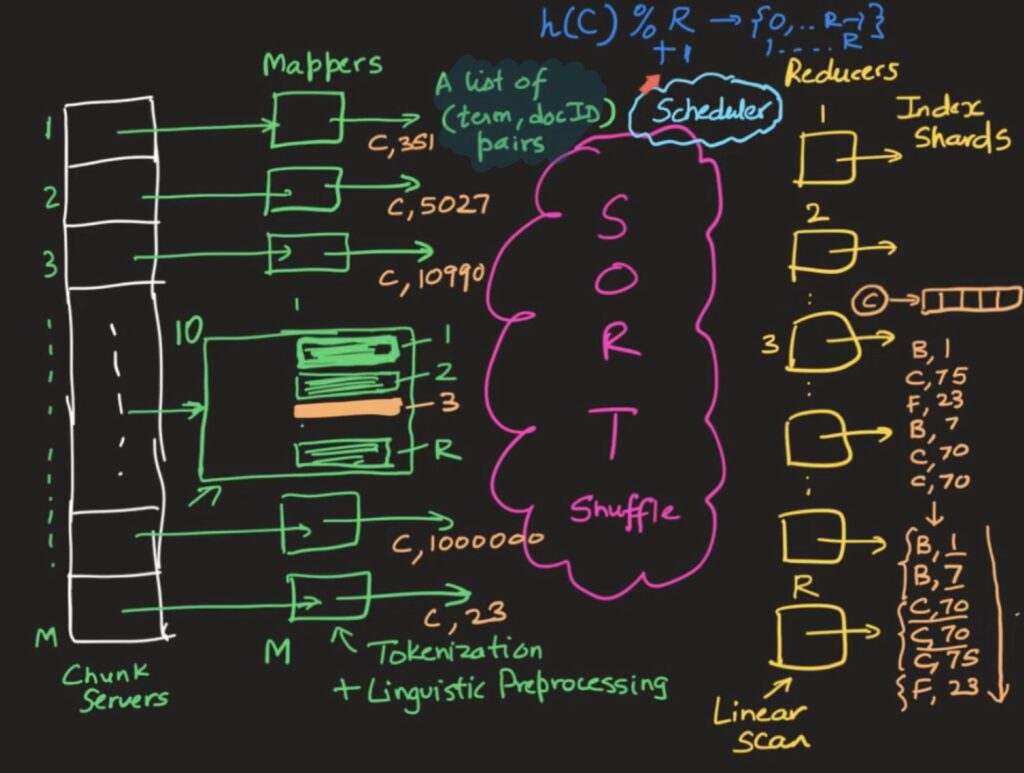
b. Map-Reduce (Batch processing)
Chunck servers has files with Term:dockid from crowlers
| Chunk server 1 | Chunk server 2 | Chunk server 3 | Chunk server 4 | … | Chunk m |
| a, 1 | a, 100 | a, 320 | a, 450 | ||
| aa, 1 | aaa, 100 | aaa, 320 | apple, 450 | ||
| abc, 2 | abc,100 | abc, 320 | avid, 450 | ||
| apple,2 | .. | … | .. | ||
| .. | .. | … | … | ||
| .. | .. | … | … |
Mappers load the file term:docid and save it to reducer files and get ready for send the data to reducer. each reducer maps to H(term)%R from term. So each reducer get all the same term from all chunk servers. And then Reducer can do external sort and merge to get SS table file for H(term)%R.When does reducer know that it gets all the data from chunk server is because of the scheduler. Mapper can sort and reduce duplicates then it can reduce datacenter’s network traffiic.
6. ETL (Extract, Transfer, Load)
By External sort and Merge, we have one global sorted Term and docID.
Chang: 20
Chang: 67
Chang: 187
From one global sorted Term and docID, The goal is to create SS Table file (Sorted String Table):
Chang: 20, 67, 187,…
Cheng: 456, 578, 2898,…
Loading the SS table to RAM: Instead of loading all the DocIDs (not feasible too big), we add only offset to save the RAM space.
Dictionary in RAM
Chang: 1245 (offset fro the file)
Cheng: 3467 (offset from the file)
Option2: In a block of the SS Table, we can set the offset of the block. Not all terms in dictionary
Dictionary in RAM
Chang: 1245 (offset)
Dannis: 3953 (offset)
Ellis: 5688 (offset)
If you tries to find Cheng, you go Chang first and search from the Cheng’s offset in the file
Benefits: you can even save more space.
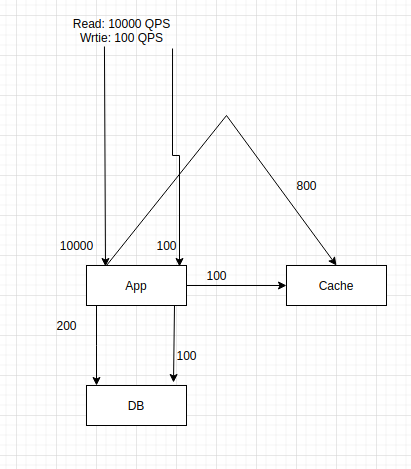
7. App tier (imported from cache or DB)
Search: Covid19 and stock crush
Get the docIDs for “Covid19” and the docIDs for “stock crush” and merge
Covid19 : [3, 23, 56, 67, 8,123,234,332,432,455,478,543,546,568,590, …….]
Stock crush : [33, 35,37,34,36,38,45,58,688,690,698,874,890,911,1221,1322, ….]
Problem. The client might not need to have all the document in advance. He might need to a few most relevant documents and that is it. But we are doing get all the docIDs from both and do and query.
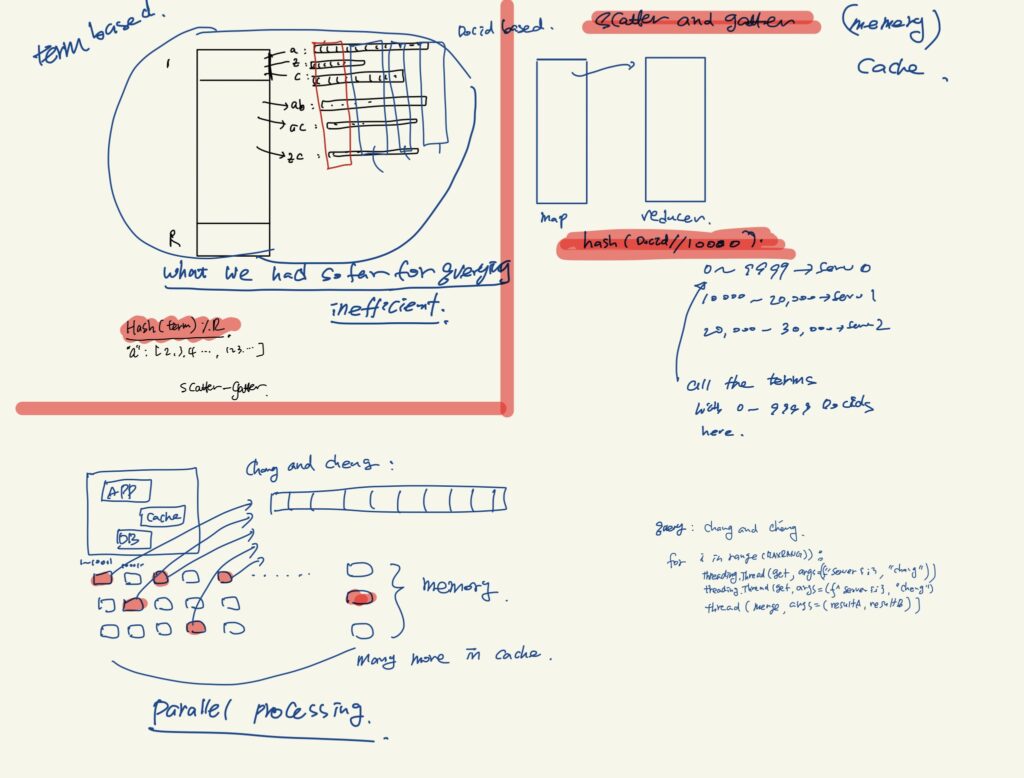
Scatter-Gather (It is good to have in Cache)
It can serve to retrieve data faster. By chunking the long list data into range, it can serve faster.